
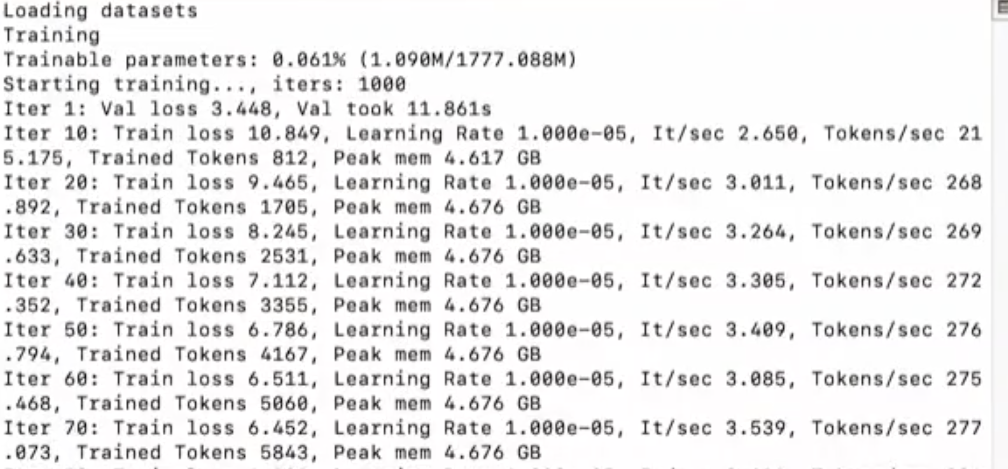
1.上面截图中的相关解释 微调训练输出日志
日志解释
加载数据集(Loading datasets):
表示模型训练开始前,数据集正在被加载。
训练(Training):
表示模型训练过程的开始。
可训练参数(Trainable parameters):
显示了模型中可训练参数的比例和数量。例如,0.061% (1.090M/1777.088M) 表示模型中有大约1.090百万个可训练参数,占总参数的0.061%。
开始训练(Starting training…):
表示模型训练的开始,并且指定了迭代次数(iters: 1000)。
迭代(Iter):
每个迭代(Iter)记录了训练过程中的一些关键指标,包括:
Val loss:验证集上的损失值,用于评估模型在未见过的数据上的表现。
Val took:完成一次验证所需的时间。
Train loss:训练集上的损失值,用于指导模型参数的更新。
Learning Rate:学习率,控制模型参数更新的步长。
It/sec:每秒迭代次数,表示训练速度。
Tokens/sec:每秒处理的标记数,表示数据处理速度。
Trained Tokens:到目前为止训练过程中处理的标记总数。
Peak mem:训练过程中达到的内存峰值。
示例解释
Iter 1:在第一次迭代中,验证集上的损失值为3.448,完成这次验证用了11.861秒。
Iter 10:在第十次迭代中,训练集上的损失值为10.849,学习率为1.000e-05,每秒迭代次数为2.650,每秒处理的标记数为215.175,到目前为止处理了812个标记,内存峰值为4.617 GB。
2.MLX lora训练相关需要修改的命令参数
2.1迭代数 –iters
迭代次数越多,可以学习损失率越低,之前命令默认迭代次数为1000,最终损失值1.863 ,可以修改下命令中的迭代参数来修改。
--iters 100002.2 学习率 –learning-rate
默认 –learning-rate 1e-5 ;解释学习率低:会训练慢,高:训练快,但是会发散,减慢收敛速度。 收敛,模型逐步稳定
--learning-rate 1e-52.3 –lora-rank 16和 –lora-alpha 32 为 LoRA层的复杂度和训练过程中的缩放因子
W=W + α * ∆W
α 是LoRA Alpha缩放因子
∆W 是 LoRA层的低秩矩阵乘积
∆W--lora-rank 16表示设置 LoRA 的秩为 16,即 r=16,这意味着 B 和 A 矩阵的维度将分别是 d×16 和 16×k。这有助于减少模型的参数量和计算复杂度。
在LoRA(Low-Rank Adaptation)的上下文中,d 和 k 通常指的是模型权重矩阵的维度,具体含义取决于模型架构和权重矩阵的位置。以下是一些常见的解释:
对于自注意力(Self-Attention)层:
d:表示模型的隐藏层维度(hidden size),即每个注意力头处理的特征向量的维度。
k:表示注意力头的数量(number of attention heads)。
对于前馈网络(Feed Forward Network, FFN)层:
d:表示模型的隐藏层维度(hidden size),即FFN层输入和输出的特征向量的维度。
k:表示FFN层内部特征的维度(intermediate size),即FFN层内部的中间特征向量的维度。通常,k 会大于 d,以增加模型的表达能力。
还是要了解一下Transformer